What Deepseek Experts Don’t Desire You To Know
 DeepSeek R1 works finest with structured inputs. Updated on 1st February – After importing the distilled mannequin, you should use the Bedrock playground for understanding distilled model responses to your inputs. This transfer gives customers with the opportunity to delve into the intricacies of the mannequin, discover its functionalities, and even integrate it into their projects for enhanced AI purposes. DeepSeek is exclusive resulting from its specialized AI mannequin, Deepseek (writexo.com)-R1, which provides distinctive customization, seamless integrations, and tailored workflows for businesses and developers. We additionally apply the generated numbered line diffs to the code file with line numbers to make sure that they are often accurately and unambiguously utilized, eliminating samples that can’t be applied because of incorrect line numbers or hallucinated content. As a result of poor diversity and high quality of synthetic information at the time, NMT approaches required datasets of (damaged, fastened) code pulled from open-supply repositories, which were often too small to provide vital enhancements over traditional approaches.
DeepSeek R1 works finest with structured inputs. Updated on 1st February – After importing the distilled mannequin, you should use the Bedrock playground for understanding distilled model responses to your inputs. This transfer gives customers with the opportunity to delve into the intricacies of the mannequin, discover its functionalities, and even integrate it into their projects for enhanced AI purposes. DeepSeek is exclusive resulting from its specialized AI mannequin, Deepseek (writexo.com)-R1, which provides distinctive customization, seamless integrations, and tailored workflows for businesses and developers. We additionally apply the generated numbered line diffs to the code file with line numbers to make sure that they are often accurately and unambiguously utilized, eliminating samples that can’t be applied because of incorrect line numbers or hallucinated content. As a result of poor diversity and high quality of synthetic information at the time, NMT approaches required datasets of (damaged, fastened) code pulled from open-supply repositories, which were often too small to provide vital enhancements over traditional approaches.
Some libraries introduce effectivity optimizations however at the cost of restricting to a small set of constructions (e.g., those representable by finite-state machines). These options clearly set DeepSeek apart, however how does it stack up towards different fashions? We additionally run Ruff and Pyright from our pyright-extended meta-LSP and assert that the expected set of diagnostics is reproduced. Because of this, diagnostics were verified with a serverless lambda that scales up in bursts. We log all LSP diagnostics from person periods in BigQuery. We distill a mannequin from synthesized diffs because fixed errors taken straight from user data are noisier than synthesized diffs. Once the model is in production, we will experiment with submit-training strategies like DPO leveraging consumer information collected by the Replit platform, corresponding to which code fixes are accepted and rejected. Over time, learning-primarily based approaches gained recognition, which leverage pairs of (broken, fastened) code to broaden the distribution of bugs and their fixes. The ultimate distribution of LSP diagnostic types in our dataset is included within the Appendix and consists of 389 samples.
The ultimate distribution of subtypes of problems in our dataset is included within the Appendix and consists of 360 samples. However, it is tough to elicit the correct distribution of responses, and to get generalist SOTA LLMs to return a persistently formatted response. We observe the bottom LLM’s information format to keep code formatting as close as doable to the model’s coaching distribution. We selected numbered Line Diffs as our goal format based mostly on (1) the discovering in OctoPack that Line Diff formatting results in larger 0-shot repair efficiency and (2) our latency requirement that the generated sequence should be as short as doable. We found that responses are extra constantly generated and formatted and, due to this fact, simpler to parse. Therefore, please test the minimum necessities first to make sure NeoChat AI: By DeepSeek V3/R1 is compatible together with your phone. By 2021, he had already constructed a compute infrastructure that will make most AI labs jealous! We want to thank Databricks and the MosaicML group for his or her support with mannequin training instruments and infrastructure. To help multiplayer options, Replit represents code as a sequence of Operational Transformations (OTs). A Replit session is a stream of information across multiple modalities.
There’s a big gap between the performance of Replit Code Repair 7B and other models (except GPT-4 Turbo). The overall performance of fashions on our real-world eval stays low when compared to the Leetcode repair eval, which demonstrates the significance of evaluating deep studying fashions on each educational and real-world benchmarks. What is the position of deep learning in DeepSeek? The whitepaper lacks deep technical details. All subsets were randomly sampled from the identical base dataset. To check how mannequin efficiency scales with finetuning dataset dimension, we finetuned DeepSeek-Coder v1.5 7B Instruct on subsets of 10K, 25K, 50K, and 75K training samples. Training LLMs is a extremely experimental course of requiring several iterations to ablate and test hypotheses. We synthesize diffs utilizing large pre-educated code LLMs with a number of-shot immediate pipeline carried out with DSPy. We first recreate the filesystem of a project at the time of the diagnostic, then use LLMs to generate and confirm artificial diffs. LSP executables should be pointed to a filesystem directory, and in a Spark environment dynamically persisting strings is challenging.
 Enhanced Research: Advanced web search and Deep-Think mode enable you discover worthwhile insights effortlessly. Millions of individuals use tools similar to ChatGPT to assist them with everyday tasks like writing emails, summarising textual content, and answering questions – and others even use them to assist with primary coding and learning. However, for quick coding help or language generation, ChatGPT stays a strong option. However, I did realise that multiple makes an attempt on the same test case did not all the time lead to promising outcomes. Immediately, inside the Console, you can even begin monitoring out-of-the-box metrics to monitor the efficiency and add customized metrics, related to your particular use case. DeepSeek V3 units a brand new normal in performance amongst open-code models. Conventional knowledge holds that giant language fashions like ChatGPT and DeepSeek must be skilled on increasingly excessive-high quality, human-created textual content to enhance; DeepSeek took another approach.
Enhanced Research: Advanced web search and Deep-Think mode enable you discover worthwhile insights effortlessly. Millions of individuals use tools similar to ChatGPT to assist them with everyday tasks like writing emails, summarising textual content, and answering questions – and others even use them to assist with primary coding and learning. However, for quick coding help or language generation, ChatGPT stays a strong option. However, I did realise that multiple makes an attempt on the same test case did not all the time lead to promising outcomes. Immediately, inside the Console, you can even begin monitoring out-of-the-box metrics to monitor the efficiency and add customized metrics, related to your particular use case. DeepSeek V3 units a brand new normal in performance amongst open-code models. Conventional knowledge holds that giant language fashions like ChatGPT and DeepSeek must be skilled on increasingly excessive-high quality, human-created textual content to enhance; DeepSeek took another approach. Better File Management: Quickly add information and extract textual content to save time on documentation. DeepSeek is engaged on subsequent-gen foundation models to push boundaries even further. The “DeepSeek AI Assistant Not Working” error sometimes stems from a mix of server outages and latest malicious assaults affecting the service. DeepSeek is also offering its R1 models underneath an open supply license, enabling free use. Is DeepSeek coder free? Completely free to use, it provides seamless and intuitive interactions for all customers. It’s absolutely open-source and available at no cost for both research and commercial use, making superior AI extra accessible to a wider viewers.
Better File Management: Quickly add information and extract textual content to save time on documentation. DeepSeek is engaged on subsequent-gen foundation models to push boundaries even further. The “DeepSeek AI Assistant Not Working” error sometimes stems from a mix of server outages and latest malicious assaults affecting the service. DeepSeek is also offering its R1 models underneath an open supply license, enabling free use. Is DeepSeek coder free? Completely free to use, it provides seamless and intuitive interactions for all customers. It’s absolutely open-source and available at no cost for both research and commercial use, making superior AI extra accessible to a wider viewers.  Productivity Boost: AI-powered tools streamline advanced tasks and make drawback-fixing extra efficient. If you’re looking for an answer tailor-made for enterprise-degree or niche applications, DeepSeek is perhaps more advantageous.
Productivity Boost: AI-powered tools streamline advanced tasks and make drawback-fixing extra efficient. If you’re looking for an answer tailor-made for enterprise-degree or niche applications, DeepSeek is perhaps more advantageous. DeepSeek, till lately a little-recognized Chinese synthetic intelligence firm, has made itself the talk of the tech industry after it rolled out a sequence of large language models that outshone many of the world’s top AI developers. Whether you need natural language processing, data analysis, or machine learning options,
DeepSeek, till lately a little-recognized Chinese synthetic intelligence firm, has made itself the talk of the tech industry after it rolled out a sequence of large language models that outshone many of the world’s top AI developers. Whether you need natural language processing, data analysis, or machine learning options, 
 Anyone managed to get deepseek (
Anyone managed to get deepseek (
 The research suggests that present medical board structures may be poorly suited to handle the widespread harm caused by physician-spread misinformation, and proposes that a patient-centered method may be inadequate to sort out public well being issues. Decolonizing world health requires a paradigm shift in how partnerships are formed and maintained. The sources said ByteDance founder Zhang Yiming is personally negotiating with knowledge middle operators across Southeast Asia and the Middle East, attempting to secure access to Nvidia’s subsequent-technology Blackwell GPUs, which are expected to turn out to be widely accessible later this year. The authors argue that these challenges have essential implications for reaching Sustainable Development Goals (SDGs) associated to universal well being protection and equitable entry to healthcare services. Successfully slicing off China from entry to HBM can be a devastating blow to the country’s AI ambitions. In short, while upholding the leadership of the Party, China is also constantly promoting comprehensive rule of law and striving to build a more just, equitable, and open social surroundings. There are still questions about precisely how it’s executed: whether it’s for the QwQ model or
The research suggests that present medical board structures may be poorly suited to handle the widespread harm caused by physician-spread misinformation, and proposes that a patient-centered method may be inadequate to sort out public well being issues. Decolonizing world health requires a paradigm shift in how partnerships are formed and maintained. The sources said ByteDance founder Zhang Yiming is personally negotiating with knowledge middle operators across Southeast Asia and the Middle East, attempting to secure access to Nvidia’s subsequent-technology Blackwell GPUs, which are expected to turn out to be widely accessible later this year. The authors argue that these challenges have essential implications for reaching Sustainable Development Goals (SDGs) associated to universal well being protection and equitable entry to healthcare services. Successfully slicing off China from entry to HBM can be a devastating blow to the country’s AI ambitions. In short, while upholding the leadership of the Party, China is also constantly promoting comprehensive rule of law and striving to build a more just, equitable, and open social surroundings. There are still questions about precisely how it’s executed: whether it’s for the QwQ model or  A couple of weeks in the past I cancelled my chatgpt subscription and bought the free trial of Google Gemini superior, since it’s presupposed to be really good at coding duties. Questions have been raised about whether the know-how may mirror state-imposed censorship or limitations on
A couple of weeks in the past I cancelled my chatgpt subscription and bought the free trial of Google Gemini superior, since it’s presupposed to be really good at coding duties. Questions have been raised about whether the know-how may mirror state-imposed censorship or limitations on  However, it was recently reported that a vulnerability in DeepSeek’s webpage exposed a significant amount of information, together with consumer chats. For cellular users, you possibly can download the app by way of the web site or scan a QR code to get began on the go. But how do you get began? If you’re in search of a quick and simple approach to get started, the web model of DeepSeek R1 is your finest guess. Whether you’re a developer, a scholar, or simply somebody interested by AI, DeepSeek R1 is a recreation-changer. Unlike proprietary AI, which is managed by a few companies, open-source fashions foster innovation, transparency, and international collaboration. It’s designed to excel in areas like conversational AI, coding, arithmetic, and advanced reasoning. DROP (Discrete Reasoning Over Paragraphs): DeepSeek V3 leads with 91.6 (F1), outperforming other models. Head over to DeepSeek AI and join using your e mail, Gmail, or phone quantity. Nvidia alone experienced a staggering decline of over $600 billion. Built on a mixture of consultants (MoE) structure, it activates 37 billion parameters per query, making it both powerful and environment friendly. Unlike standard AI fashions that utilize all their computational blocks for every job,
However, it was recently reported that a vulnerability in DeepSeek’s webpage exposed a significant amount of information, together with consumer chats. For cellular users, you possibly can download the app by way of the web site or scan a QR code to get began on the go. But how do you get began? If you’re in search of a quick and simple approach to get started, the web model of DeepSeek R1 is your finest guess. Whether you’re a developer, a scholar, or simply somebody interested by AI, DeepSeek R1 is a recreation-changer. Unlike proprietary AI, which is managed by a few companies, open-source fashions foster innovation, transparency, and international collaboration. It’s designed to excel in areas like conversational AI, coding, arithmetic, and advanced reasoning. DROP (Discrete Reasoning Over Paragraphs): DeepSeek V3 leads with 91.6 (F1), outperforming other models. Head over to DeepSeek AI and join using your e mail, Gmail, or phone quantity. Nvidia alone experienced a staggering decline of over $600 billion. Built on a mixture of consultants (MoE) structure, it activates 37 billion parameters per query, making it both powerful and environment friendly. Unlike standard AI fashions that utilize all their computational blocks for every job, 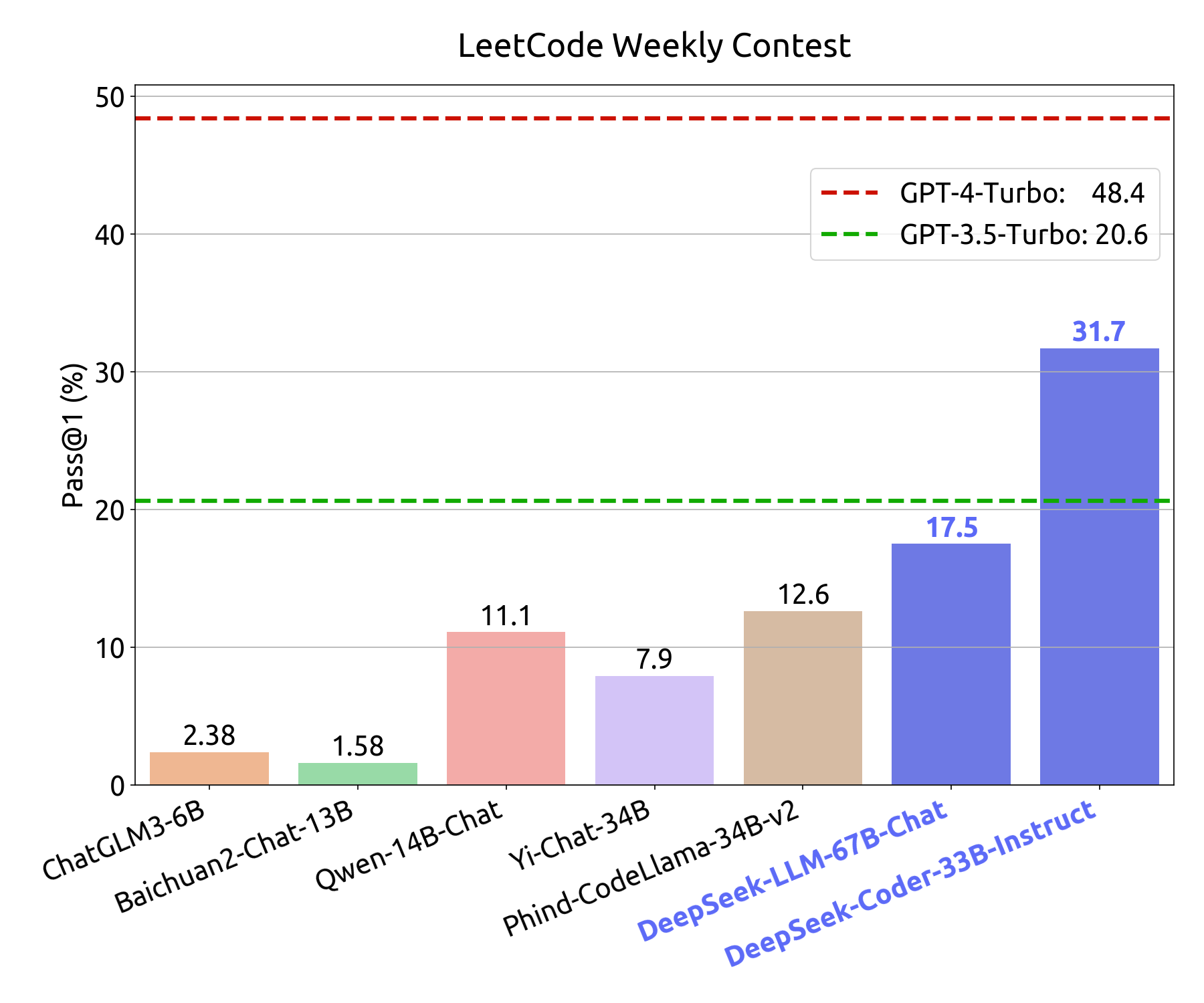 If you’re a developer or someone who values privacy and pace, operating DeepSeek R1 regionally is a great choice. Batches of account details have been being purchased by a drug cartel, who linked the client accounts to easily obtainable personal details (like addresses) to facilitate nameless transactions, permitting a significant amount of funds to maneuver throughout international borders with out leaving a signature. Even more impressively, they’ve executed this fully in simulation then transferred the brokers to actual world robots who are capable of play 1v1 soccer towards eachother. And though that has happened before, too much of oldsters are anxious that this time he’s truly right. Compressor abstract: The text describes a method to seek out and analyze patterns of following behavior between two time sequence, comparable to human movements or inventory market fluctuations, using the Matrix Profile Method. Compressor abstract: The text describes a technique to visualize neuron conduct in deep neural networks using an improved encoder-decoder mannequin with a number of consideration mechanisms, achieving higher outcomes on lengthy sequence neuron captioning. Compressor abstract: The Locally Adaptive Morphable Model (LAMM) is an Auto-Encoder framework that learns to generate and manipulate 3D meshes with local management, achieving state-of-the-art performance in disentangling geometry manipulation and reconstruction.
If you’re a developer or someone who values privacy and pace, operating DeepSeek R1 regionally is a great choice. Batches of account details have been being purchased by a drug cartel, who linked the client accounts to easily obtainable personal details (like addresses) to facilitate nameless transactions, permitting a significant amount of funds to maneuver throughout international borders with out leaving a signature. Even more impressively, they’ve executed this fully in simulation then transferred the brokers to actual world robots who are capable of play 1v1 soccer towards eachother. And though that has happened before, too much of oldsters are anxious that this time he’s truly right. Compressor abstract: The text describes a method to seek out and analyze patterns of following behavior between two time sequence, comparable to human movements or inventory market fluctuations, using the Matrix Profile Method. Compressor abstract: The text describes a technique to visualize neuron conduct in deep neural networks using an improved encoder-decoder mannequin with a number of consideration mechanisms, achieving higher outcomes on lengthy sequence neuron captioning. Compressor abstract: The Locally Adaptive Morphable Model (LAMM) is an Auto-Encoder framework that learns to generate and manipulate 3D meshes with local management, achieving state-of-the-art performance in disentangling geometry manipulation and reconstruction. Compressor summary: The paper presents Raise, a new structure that integrates massive language fashions into conversational agents using a twin-component reminiscence system, bettering their controllability and adaptability in complicated dialogues, as proven by its efficiency in an actual property gross sales context. Compressor abstract: The paper introduces a parameter environment friendly framework for positive-tuning multimodal large language fashions to enhance medical visible query answering efficiency, reaching high accuracy and outperforming GPT-4v. Compressor summary: The paper introduces a new community known as TSP-RDANet that divides picture denoising into two phases and uses totally different consideration mechanisms to be taught vital options and suppress irrelevant ones, reaching higher performance than current strategies. Compressor summary: MCoRe is a novel framework for video-based mostly action high quality assessment that segments movies into stages and uses stage-wise contrastive studying to improve performance. Compressor abstract: The paper proposes a technique that uses lattice output from ASR programs to enhance SLU duties by incorporating phrase confusion networks, enhancing LLM’s resilience to noisy speech transcripts and robustness to various ASR efficiency conditions.
Compressor summary: The paper presents Raise, a new structure that integrates massive language fashions into conversational agents using a twin-component reminiscence system, bettering their controllability and adaptability in complicated dialogues, as proven by its efficiency in an actual property gross sales context. Compressor abstract: The paper introduces a parameter environment friendly framework for positive-tuning multimodal large language fashions to enhance medical visible query answering efficiency, reaching high accuracy and outperforming GPT-4v. Compressor summary: The paper introduces a new community known as TSP-RDANet that divides picture denoising into two phases and uses totally different consideration mechanisms to be taught vital options and suppress irrelevant ones, reaching higher performance than current strategies. Compressor summary: MCoRe is a novel framework for video-based mostly action high quality assessment that segments movies into stages and uses stage-wise contrastive studying to improve performance. Compressor abstract: The paper proposes a technique that uses lattice output from ASR programs to enhance SLU duties by incorporating phrase confusion networks, enhancing LLM’s resilience to noisy speech transcripts and robustness to various ASR efficiency conditions.
 When evaluating model outputs on Hugging Face with those on platforms oriented in the direction of the Chinese viewers, fashions subject to less stringent censorship supplied extra substantive solutions to politically nuanced inquiries. The integrated censorship mechanisms and restrictions can solely be removed to a limited extent in the open-source version of the R1 model. You can too employ vLLM for prime-throughput inference. I’ll consider including 32g as well if there is curiosity, and once I’ve performed perplexity and analysis comparisons, but at the moment 32g fashions are nonetheless not fully examined with AutoAWQ and vLLM. They lowered communication by rearranging (each 10 minutes) the precise machine every skilled was on in order to keep away from sure machines being queried extra often than the others, including auxiliary load-balancing losses to the training loss operate, and different load-balancing techniques. They discovered this to help with skilled balancing. Expert models had been used, as an alternative of R1 itself, because the output from R1 itself suffered “overthinking, poor formatting, and extreme size”. For Budget Constraints: If you’re restricted by budget, give attention to Deepseek GGML/GGUF models that fit within the sytem RAM. RAM wanted to load the model initially. 4. The mannequin will begin downloading.
When evaluating model outputs on Hugging Face with those on platforms oriented in the direction of the Chinese viewers, fashions subject to less stringent censorship supplied extra substantive solutions to politically nuanced inquiries. The integrated censorship mechanisms and restrictions can solely be removed to a limited extent in the open-source version of the R1 model. You can too employ vLLM for prime-throughput inference. I’ll consider including 32g as well if there is curiosity, and once I’ve performed perplexity and analysis comparisons, but at the moment 32g fashions are nonetheless not fully examined with AutoAWQ and vLLM. They lowered communication by rearranging (each 10 minutes) the precise machine every skilled was on in order to keep away from sure machines being queried extra often than the others, including auxiliary load-balancing losses to the training loss operate, and different load-balancing techniques. They discovered this to help with skilled balancing. Expert models had been used, as an alternative of R1 itself, because the output from R1 itself suffered “overthinking, poor formatting, and extreme size”. For Budget Constraints: If you’re restricted by budget, give attention to Deepseek GGML/GGUF models that fit within the sytem RAM. RAM wanted to load the model initially. 4. The mannequin will begin downloading.
![[New Single]: Timsong - Yahweh](https://www.thechristgospelradio.com/wp-content/uploads/2021/06/Yahweh-Timsong.jpg) Its state-of-the-artwork efficiency across varied benchmarks signifies sturdy capabilities in the most common programming languages. This model achieves state-of-the-art performance on a number of programming languages and benchmarks. Surprisingly, our DeepSeek-Coder-Base-7B reaches the efficiency of CodeLlama-34B. Now, it is not essentially that they do not like Vite, it’s that they want to give everybody a fair shake when talking about that deprecation. They generate different responses on Hugging Face and on the China-facing platforms, give completely different solutions in English and Chinese, and sometimes change their stances when prompted multiple times in the identical language. Read more: DeepSeek LLM: Scaling Open-Source Language Models with Longtermism (arXiv). It’s licensed beneath the MIT License for the code repository, with the usage of fashions being topic to the Model License. It’s nonetheless there and presents no warning of being dead except for the npm audit. Are you aware why folks nonetheless massively use “create-react-app”? Does this still matter, given what DeepSeek has achieved? “Time will inform if the DeepSeek menace is real – the race is on as to what expertise works and how the large Western gamers will respond and evolve,” stated Michael Block, market strategist at Third Seven Capital. So all this time wasted on serious about it because they did not wish to lose the publicity and “brand recognition” of create-react-app implies that now, create-react-app is broken and will proceed to bleed utilization as we all continue to inform folks not to make use of it since vitejs works completely tremendous.
Its state-of-the-artwork efficiency across varied benchmarks signifies sturdy capabilities in the most common programming languages. This model achieves state-of-the-art performance on a number of programming languages and benchmarks. Surprisingly, our DeepSeek-Coder-Base-7B reaches the efficiency of CodeLlama-34B. Now, it is not essentially that they do not like Vite, it’s that they want to give everybody a fair shake when talking about that deprecation. They generate different responses on Hugging Face and on the China-facing platforms, give completely different solutions in English and Chinese, and sometimes change their stances when prompted multiple times in the identical language. Read more: DeepSeek LLM: Scaling Open-Source Language Models with Longtermism (arXiv). It’s licensed beneath the MIT License for the code repository, with the usage of fashions being topic to the Model License. It’s nonetheless there and presents no warning of being dead except for the npm audit. Are you aware why folks nonetheless massively use “create-react-app”? Does this still matter, given what DeepSeek has achieved? “Time will inform if the DeepSeek menace is real – the race is on as to what expertise works and how the large Western gamers will respond and evolve,” stated Michael Block, market strategist at Third Seven Capital. So all this time wasted on serious about it because they did not wish to lose the publicity and “brand recognition” of create-react-app implies that now, create-react-app is broken and will proceed to bleed utilization as we all continue to inform folks not to make use of it since vitejs works completely tremendous.