Cool Little Deepseek Device
 DeepSeek API is an AI-powered instrument that simplifies complicated data searches using superior algorithms and pure language processing. DeepSeek-V2 brought another of DeepSeek’s innovations – Multi-Head Latent Attention (MLA), a modified attention mechanism for Transformers that permits faster info processing with much less memory utilization. Coming from China, DeepSeek’s technical improvements are turning heads in Silicon Valley. Writing short fiction. Hallucinations should not an issue; they’re a function! Enable Two-Factor Authentication (2FA): For added safety, activate 2FA if DeepSeek gives this function. Amazon Bedrock Marketplace offers over one hundred well-liked, rising, and specialised FMs alongside the current selection of business-leading fashions in Amazon Bedrock. DeepSeek API gives flexible pricing tailored to your business needs. Designed to scale with your business needs, DeepSeek API ensures secure and dependable data handling, assembly business requirements for data privacy. DeepSeek API employs advanced AI algorithms to interpret and execute advanced queries, delivering accurate and contextually related results throughout structured and unstructured knowledge. 4. Output Delivery: Results are ranked, refined, and delivered in a consumer-pleasant format. These strategies improved its performance on mathematical benchmarks, achieving go rates of 63.5% on the high-faculty level miniF2F check and 25.3% on the undergraduate-degree ProofNet check, setting new state-of-the-artwork results. Its aggressive pricing, comprehensive context support, and improved efficiency metrics are positive to make it stand above a few of its rivals for numerous functions.
DeepSeek API is an AI-powered instrument that simplifies complicated data searches using superior algorithms and pure language processing. DeepSeek-V2 brought another of DeepSeek’s innovations – Multi-Head Latent Attention (MLA), a modified attention mechanism for Transformers that permits faster info processing with much less memory utilization. Coming from China, DeepSeek’s technical improvements are turning heads in Silicon Valley. Writing short fiction. Hallucinations should not an issue; they’re a function! Enable Two-Factor Authentication (2FA): For added safety, activate 2FA if DeepSeek gives this function. Amazon Bedrock Marketplace offers over one hundred well-liked, rising, and specialised FMs alongside the current selection of business-leading fashions in Amazon Bedrock. DeepSeek API gives flexible pricing tailored to your business needs. Designed to scale with your business needs, DeepSeek API ensures secure and dependable data handling, assembly business requirements for data privacy. DeepSeek API employs advanced AI algorithms to interpret and execute advanced queries, delivering accurate and contextually related results throughout structured and unstructured knowledge. 4. Output Delivery: Results are ranked, refined, and delivered in a consumer-pleasant format. These strategies improved its performance on mathematical benchmarks, achieving go rates of 63.5% on the high-faculty level miniF2F check and 25.3% on the undergraduate-degree ProofNet check, setting new state-of-the-artwork results. Its aggressive pricing, comprehensive context support, and improved efficiency metrics are positive to make it stand above a few of its rivals for numerous functions.
 You dream it, we make it. Get again JSON in the format you want. If you would like the exact step-by-step directions, I’ve included it inside the video notes from right this moment, hyperlink within the feedback description. From the outset, it was free for industrial use and totally open-source. Free for business use and totally open-supply. 2. Is DeepSeek AI free to make use of? From startups to enterprises, the scalable plans ensure you pay only for what you employ. Healthcare: Optimizing therapy plans and predictive diagnostics. • Healthcare: Access vital medical data, research papers, and clinical information efficiently. The newest version, DeepSeek-V2, introduces improved accuracy, quicker query responses, and enhanced customization for simpler information searches. ChatGPT provides extra user-pleasant customization options, making it more accessible to a broader viewers. The benefit the corporate provides is for medium to enterprise-degree e-commerce customers, which is being enabled on online/mobile channels leveraging greatest in class algorithms giving near-human experience. Try the Deepseek R1 Lite preview in the present day and experience the way forward for productiveness! Later, on November 29, 2023, DeepSeek launched DeepSeek LLM, described because the “next frontier of open-source LLMs,” scaled up to 67B parameters. In February 2024, DeepSeek introduced a specialized model, DeepSeekMath, with 7B parameters.
You dream it, we make it. Get again JSON in the format you want. If you would like the exact step-by-step directions, I’ve included it inside the video notes from right this moment, hyperlink within the feedback description. From the outset, it was free for industrial use and totally open-source. Free for business use and totally open-supply. 2. Is DeepSeek AI free to make use of? From startups to enterprises, the scalable plans ensure you pay only for what you employ. Healthcare: Optimizing therapy plans and predictive diagnostics. • Healthcare: Access vital medical data, research papers, and clinical information efficiently. The newest version, DeepSeek-V2, introduces improved accuracy, quicker query responses, and enhanced customization for simpler information searches. ChatGPT provides extra user-pleasant customization options, making it more accessible to a broader viewers. The benefit the corporate provides is for medium to enterprise-degree e-commerce customers, which is being enabled on online/mobile channels leveraging greatest in class algorithms giving near-human experience. Try the Deepseek R1 Lite preview in the present day and experience the way forward for productiveness! Later, on November 29, 2023, DeepSeek launched DeepSeek LLM, described because the “next frontier of open-source LLMs,” scaled up to 67B parameters. In February 2024, DeepSeek introduced a specialized model, DeepSeekMath, with 7B parameters.
Later in March 2024, DeepSeek tried their hand at vision fashions and launched DeepSeek-VL for high-high quality imaginative and prescient-language understanding. The freshest model, launched by DeepSeek in August 2024, is an optimized model of their open-source mannequin for theorem proving in Lean 4, DeepSeek-Prover-V1.5. In January 2024, this resulted within the creation of more advanced and efficient fashions like DeepSeekMoE, which featured a sophisticated Mixture-of-Experts architecture, and a new model of their Coder, DeepSeek-Coder-v1.5. This time developers upgraded the previous version of their Coder and now DeepSeek-Coder-V2 helps 338 languages and 128K context size. DeepSeek is all the rave right now. On November 2, 2023, DeepSeek started quickly unveiling its fashions, beginning with DeepSeek Coder. But, like many fashions, it confronted challenges in computational effectivity and scalability. This is exemplified in their DeepSeek-V2 and DeepSeek-Coder-V2 models, with the latter extensively considered one of the strongest open-supply code models accessible. DeepSeek-Coder-V2 is the first open-supply AI mannequin to surpass GPT4-Turbo in coding and math, which made it one of the most acclaimed new fashions. Both are built on DeepSeek’s upgraded Mixture-of-Experts strategy, first used in DeepSeekMoE. Initially, DeepSeek created their first model with architecture just like other open models like LLaMA, aiming to outperform benchmarks.
• Advanced Technology: Backed by the newest in AI and NLP analysis, together with collaborations with platforms like HuggingFace. • Reliability: Trusted by world corporations for mission-crucial data search and retrieval duties. Such a bias is tough to identify, since most models are trained on massive databases and companies are reluctant to share their coaching data. 3. Search Execution: DeepSeek scans linked databases or data streams to extract relevant data. Expand your international reach with DeepSeek’s capability to process queries and information in a number of languages, catering to diverse user needs. Perform high-pace searches and gain prompt insights with DeepSeek’s real-time analytics, ideal for time-sensitive operations. The context dimension is the largest number of tokens the LLM can handle without delay, enter plus output.  Launching DeepSeek LLM! Next Frontier of Open-Source LLMs! DeepSeek fashions shortly gained reputation upon release. While much consideration in the AI community has been focused on fashions like LLaMA and Mistral, DeepSeek has emerged as a significant player that deserves closer examination.
Launching DeepSeek LLM! Next Frontier of Open-Source LLMs! DeepSeek fashions shortly gained reputation upon release. While much consideration in the AI community has been focused on fashions like LLaMA and Mistral, DeepSeek has emerged as a significant player that deserves closer examination.
If you liked this write-up and you would such as to obtain additional information concerning ديب سيك kindly browse through the web site.
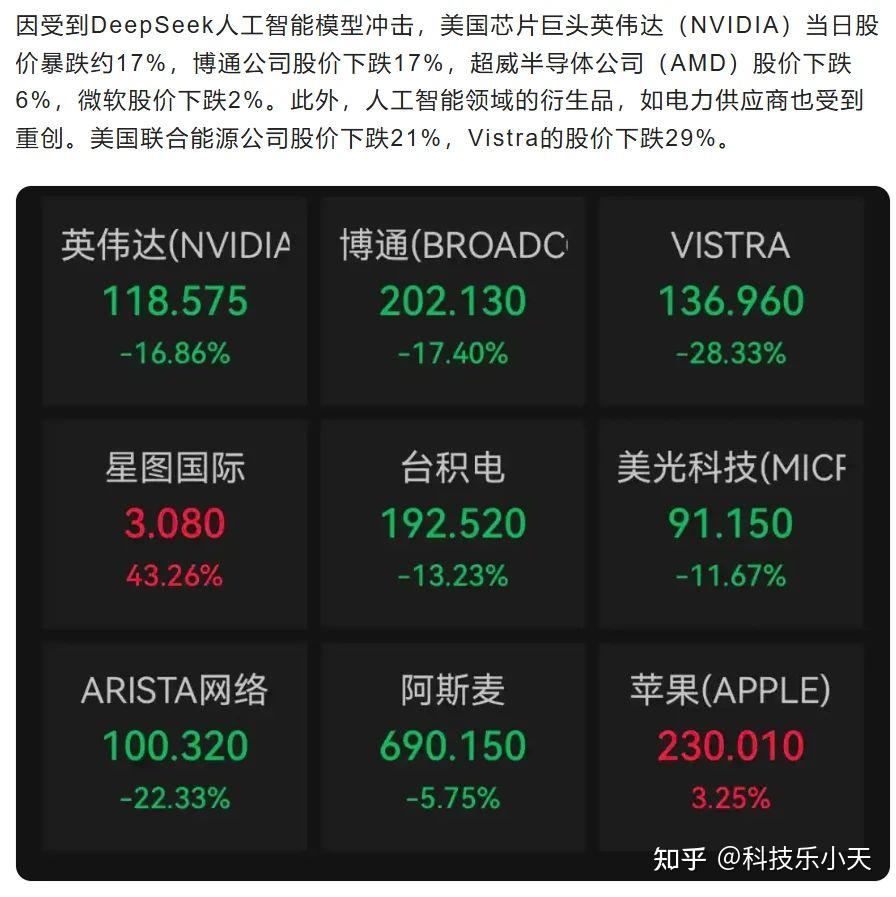


 The researchers plan to extend DeepSeek-Prover’s data to extra advanced mathematical fields. 93.06% on a subset of the MedQA dataset that covers main respiratory diseases,” the researchers write. The mannequin was pretrained on “a diverse and excessive-quality corpus comprising 8.1 trillion tokens” (and as is widespread today, no other information concerning the dataset is accessible.) “We conduct all experiments on a cluster geared up with NVIDIA H800 GPUs. LLM v0.6.6 helps DeepSeek-V3 inference for FP8 and BF16 modes on both NVIDIA and AMD GPUs. Below, we element the wonderful-tuning process and inference methods for every mannequin. The mannequin learn psychology texts and built software program for administering character exams. Its chatbot reportedly solutions questions, solves logic issues, and writes pc packages on par with different chatbots in the marketplace, according to benchmark checks utilized by American AI companies. This paper presents a brand new benchmark known as CodeUpdateArena to evaluate how nicely massive language models (LLMs) can replace their information about evolving code APIs, a crucial limitation of current approaches.
The researchers plan to extend DeepSeek-Prover’s data to extra advanced mathematical fields. 93.06% on a subset of the MedQA dataset that covers main respiratory diseases,” the researchers write. The mannequin was pretrained on “a diverse and excessive-quality corpus comprising 8.1 trillion tokens” (and as is widespread today, no other information concerning the dataset is accessible.) “We conduct all experiments on a cluster geared up with NVIDIA H800 GPUs. LLM v0.6.6 helps DeepSeek-V3 inference for FP8 and BF16 modes on both NVIDIA and AMD GPUs. Below, we element the wonderful-tuning process and inference methods for every mannequin. The mannequin learn psychology texts and built software program for administering character exams. Its chatbot reportedly solutions questions, solves logic issues, and writes pc packages on par with different chatbots in the marketplace, according to benchmark checks utilized by American AI companies. This paper presents a brand new benchmark known as CodeUpdateArena to evaluate how nicely massive language models (LLMs) can replace their information about evolving code APIs, a crucial limitation of current approaches. This unique funding model has allowed DeepSeek to pursue ambitious AI initiatives with out the stress of exterior investors, enabling it to prioritize long-term research and improvement. Currently, he works as the top of development at Gegenfeld and an instructor, here on Udemy. Ole N. Mai gained his experience as knowledgeable instructor and coach for younger startups and founders at Gegenfeld and his studies in economics. Ultimately, the authors stress that maintaining skilled integrity is crucial for guaranteeing that contributions to authorized proceedings are accurate and unbiased, thereby upholding the moral standards of the career. But that’s not all-I’ll also present you the way to install DeepSeek domestically on your system for offline use, making certain full control over your AI setting. 2014I’ll additionally present you how to install DeepSeek domestically in your system for offline use, guaranteeing full management over your AI atmosphere. BYOK customers ought to test with their supplier in the event that they assist Claude 3.5 Sonnet for his or her particular deployment environment. The mannequin is deployed in an AWS safe surroundings and under your digital personal cloud (VPC) controls, serving to to assist information security.
This unique funding model has allowed DeepSeek to pursue ambitious AI initiatives with out the stress of exterior investors, enabling it to prioritize long-term research and improvement. Currently, he works as the top of development at Gegenfeld and an instructor, here on Udemy. Ole N. Mai gained his experience as knowledgeable instructor and coach for younger startups and founders at Gegenfeld and his studies in economics. Ultimately, the authors stress that maintaining skilled integrity is crucial for guaranteeing that contributions to authorized proceedings are accurate and unbiased, thereby upholding the moral standards of the career. But that’s not all-I’ll also present you the way to install DeepSeek domestically on your system for offline use, making certain full control over your AI setting. 2014I’ll additionally present you how to install DeepSeek domestically in your system for offline use, guaranteeing full management over your AI atmosphere. BYOK customers ought to test with their supplier in the event that they assist Claude 3.5 Sonnet for his or her particular deployment environment. The mannequin is deployed in an AWS safe surroundings and under your digital personal cloud (VPC) controls, serving to to assist information security.
 Just log into the free course, then go to AI brokers after which go to DeepSeek R1. So that’s another free API you need to use as well. And then for example, in the event you wanna use Gemini, we are able to say, for example, Gemini Flash Experimental, plug in the API key and we ought to be good to go. So for example, if we’re using Gemini Flash Thinking, it’s now analyzing the web page. Now it is navigating over to Google and it is typed in really quickly truly, cheapest flights from Bangkok to the UK in July. Prefer it cannot really use Google Maps and it’s truly blocked from utilizing YouTube. After which from here, you possibly can simply just begin using net browser, pretty simple and easy to do. So first place you are gonna begin is by installing browser use WebUI, proper? And from right here, you can start installing any sort of mannequin you need with AI without cost domestically. Number two, you can have a free AI agent.
Just log into the free course, then go to AI brokers after which go to DeepSeek R1. So that’s another free API you need to use as well. And then for example, in the event you wanna use Gemini, we are able to say, for example, Gemini Flash Experimental, plug in the API key and we ought to be good to go. So for example, if we’re using Gemini Flash Thinking, it’s now analyzing the web page. Now it is navigating over to Google and it is typed in really quickly truly, cheapest flights from Bangkok to the UK in July. Prefer it cannot really use Google Maps and it’s truly blocked from utilizing YouTube. After which from here, you possibly can simply just begin using net browser, pretty simple and easy to do. So first place you are gonna begin is by installing browser use WebUI, proper? And from right here, you can start installing any sort of mannequin you need with AI without cost domestically. Number two, you can have a free AI agent. For each enter, only the related specialists are activated, making certain efficient use of computational assets. From the MoE framework, it takes load balancing to distribute tasks amongst consultants and top-ok gating to pick out probably the most relevant specialists. This method permits
For each enter, only the related specialists are activated, making certain efficient use of computational assets. From the MoE framework, it takes load balancing to distribute tasks amongst consultants and top-ok gating to pick out probably the most relevant specialists. This method permits 
 The development of the neural community took two months, costing $5.58 million and requiring considerably fewer computational resources in comparison with larger tech firms. 0.14 per million tokens compared to $7.5 for its American competitor. These challenges may influence its progress and adoption, particularly when it comes to useful resource allocation and the effectiveness of its modern approach in comparison with proprietary fashions. This method not solely mitigates useful resource constraints but in addition accelerates the event of reducing-edge technologies. Founded in 2023 by Liang Wenfeng, a former head of the High-Flyer quantitative hedge fund,
The development of the neural community took two months, costing $5.58 million and requiring considerably fewer computational resources in comparison with larger tech firms. 0.14 per million tokens compared to $7.5 for its American competitor. These challenges may influence its progress and adoption, particularly when it comes to useful resource allocation and the effectiveness of its modern approach in comparison with proprietary fashions. This method not solely mitigates useful resource constraints but in addition accelerates the event of reducing-edge technologies. Founded in 2023 by Liang Wenfeng, a former head of the High-Flyer quantitative hedge fund,  Through the dynamic adjustment, DeepSeek-V3 retains balanced professional load during training, and achieves higher performance than models that encourage load steadiness via pure auxiliary losses. Because of the effective load balancing technique, DeepSeek-V3 keeps a very good load stability during its full training. Per Deepseek, their model stands out for its reasoning capabilities, achieved through revolutionary training strategies such as reinforcement learning.
Through the dynamic adjustment, DeepSeek-V3 retains balanced professional load during training, and achieves higher performance than models that encourage load steadiness via pure auxiliary losses. Because of the effective load balancing technique, DeepSeek-V3 keeps a very good load stability during its full training. Per Deepseek, their model stands out for its reasoning capabilities, achieved through revolutionary training strategies such as reinforcement learning.  In a groundbreaking (and chilling) leap, scientists have unveiled AI programs capable of replicating themselves. I remember going up to the robotic lab at UC Berkeley and watching very primitive convnet primarily based techniques performing tasks way more basic than this and incredibly slowly and sometimes badly. Basic Architecture of DeepSeekMoE. Compared with DeepSeek-V2, an exception is that we moreover introduce an auxiliary-loss-free load balancing technique (Wang et al., 2024a) for DeepSeekMoE to mitigate the efficiency degradation induced by the hassle to ensure load stability. For Feed-Forward Networks (FFNs),
In a groundbreaking (and chilling) leap, scientists have unveiled AI programs capable of replicating themselves. I remember going up to the robotic lab at UC Berkeley and watching very primitive convnet primarily based techniques performing tasks way more basic than this and incredibly slowly and sometimes badly. Basic Architecture of DeepSeekMoE. Compared with DeepSeek-V2, an exception is that we moreover introduce an auxiliary-loss-free load balancing technique (Wang et al., 2024a) for DeepSeekMoE to mitigate the efficiency degradation induced by the hassle to ensure load stability. For Feed-Forward Networks (FFNs),