4 Simple Tactics For Deepseek Uncovered
 DeepSeek wins the gold star for towing the Party line. The thrill of seeing your first line of code come to life – it’s a feeling each aspiring developer knows! Today, we draw a transparent line in the digital sand – any infringement on our cybersecurity will meet swift consequences. It’ll lower prices and cut back inflation and due to this fact curiosity rates. I instructed myself If I could do one thing this beautiful with just those guys, what’s going to occur after i add JavaScript? Please enable JavaScript in your browser settings. A picture of an online interface displaying a settings page with the title “deepseeek-chat” in the top box. All these settings are something I will keep tweaking to get the best output and I’m additionally gonna keep testing new fashions as they grow to be out there. A extra speculative prediction is that we are going to see a RoPE alternative or at the very least a variant. I don’t know whether or not AI developers will take the next step and obtain what’s referred to as the “singularity”, where AI fully exceeds what the neurons and synapses of the human mind are doing, however I feel they may. This paper presents a brand new benchmark known as CodeUpdateArena to guage how nicely large language models (LLMs) can update their information about evolving code APIs, a vital limitation of present approaches.
DeepSeek wins the gold star for towing the Party line. The thrill of seeing your first line of code come to life – it’s a feeling each aspiring developer knows! Today, we draw a transparent line in the digital sand – any infringement on our cybersecurity will meet swift consequences. It’ll lower prices and cut back inflation and due to this fact curiosity rates. I instructed myself If I could do one thing this beautiful with just those guys, what’s going to occur after i add JavaScript? Please enable JavaScript in your browser settings. A picture of an online interface displaying a settings page with the title “deepseeek-chat” in the top box. All these settings are something I will keep tweaking to get the best output and I’m additionally gonna keep testing new fashions as they grow to be out there. A extra speculative prediction is that we are going to see a RoPE alternative or at the very least a variant. I don’t know whether or not AI developers will take the next step and obtain what’s referred to as the “singularity”, where AI fully exceeds what the neurons and synapses of the human mind are doing, however I feel they may. This paper presents a brand new benchmark known as CodeUpdateArena to guage how nicely large language models (LLMs) can update their information about evolving code APIs, a vital limitation of present approaches.
 The paper presents a brand new large language mannequin called DeepSeekMath 7B that’s specifically designed to excel at mathematical reasoning. The paper presents the CodeUpdateArena benchmark to check how nicely giant language fashions (LLMs) can update their data about code APIs which might be constantly evolving. The paper presents a compelling strategy to enhancing the mathematical reasoning capabilities of large language models, and the outcomes achieved by DeepSeekMath 7B are spectacular. Despite these potential areas for further exploration, the overall method and the outcomes introduced in the paper signify a big step forward in the sphere of giant language models for mathematical reasoning. However, there are a couple of potential limitations and areas for further research that may very well be thought of. While DeepSeek-Coder-V2-0724 slightly outperformed in HumanEval Multilingual and Aider tests, each variations performed comparatively low within the SWE-verified check, indicating areas for further improvement. Within the coding area, DeepSeek-V2.5 retains the highly effective code capabilities of DeepSeek-Coder-V2-0724. Additionally, it possesses glorious mathematical and reasoning skills, and its basic capabilities are on par with DeepSeek-V2-0517. The deepseek-chat model has been upgraded to DeepSeek-V2-0517. DeepSeek R1 is now accessible within the mannequin catalog on Azure AI Foundry and GitHub, becoming a member of a various portfolio of over 1,800 fashions, including frontier, open-supply, industry-specific, and activity-primarily based AI fashions.
The paper presents a brand new large language mannequin called DeepSeekMath 7B that’s specifically designed to excel at mathematical reasoning. The paper presents the CodeUpdateArena benchmark to check how nicely giant language fashions (LLMs) can update their data about code APIs which might be constantly evolving. The paper presents a compelling strategy to enhancing the mathematical reasoning capabilities of large language models, and the outcomes achieved by DeepSeekMath 7B are spectacular. Despite these potential areas for further exploration, the overall method and the outcomes introduced in the paper signify a big step forward in the sphere of giant language models for mathematical reasoning. However, there are a couple of potential limitations and areas for further research that may very well be thought of. While DeepSeek-Coder-V2-0724 slightly outperformed in HumanEval Multilingual and Aider tests, each variations performed comparatively low within the SWE-verified check, indicating areas for further improvement. Within the coding area, DeepSeek-V2.5 retains the highly effective code capabilities of DeepSeek-Coder-V2-0724. Additionally, it possesses glorious mathematical and reasoning skills, and its basic capabilities are on par with DeepSeek-V2-0517. The deepseek-chat model has been upgraded to DeepSeek-V2-0517. DeepSeek R1 is now accessible within the mannequin catalog on Azure AI Foundry and GitHub, becoming a member of a various portfolio of over 1,800 fashions, including frontier, open-supply, industry-specific, and activity-primarily based AI fashions.
In distinction to the standard instruction finetuning used to finetune code models, we didn’t use natural language directions for our code repair mannequin. The cumulative query of how a lot whole compute is used in experimentation for a mannequin like this is much trickier. But after looking through the WhatsApp documentation and Indian Tech Videos (yes, all of us did look on the Indian IT Tutorials), it wasn’t actually a lot of a unique from Slack. DeepSeek is “AI’s Sputnik second,” Marc Andreessen, a tech enterprise capitalist, posted on social media on Sunday. What is the difference between DeepSeek LLM and different language fashions? As the field of large language models for mathematical reasoning continues to evolve, the insights and techniques presented in this paper are likely to inspire additional advancements and contribute to the event of much more capable and versatile mathematical AI programs. The paper introduces DeepSeekMath 7B, a big language model that has been pre-trained on an enormous amount of math-related information from Common Crawl, totaling 120 billion tokens.
In DeepSeek-V2.5, we’ve extra clearly defined the boundaries of mannequin safety, strengthening its resistance to jailbreak attacks whereas decreasing the overgeneralization of safety policies to regular queries. Balancing security and helpfulness has been a key focus during our iterative development. In case your focus is on superior modeling, the Deep Seek model adapts intuitively to your prompts. Hermes-2-Theta-Llama-3-8B is a cutting-edge language mannequin created by Nous Research. The analysis represents an necessary step ahead in the ongoing efforts to develop massive language models that can effectively sort out complicated mathematical problems and reasoning duties. Sit up for multimodal assist and other slicing-edge options within the deepseek ai ecosystem. However, the knowledge these models have is static – it doesn’t change even because the precise code libraries and APIs they depend on are continuously being up to date with new options and changes. Points 2 and three are basically about my financial assets that I don’t have out there for the time being. First a little bit again story: After we saw the birth of Co-pilot so much of various rivals have come onto the display screen products like Supermaven, cursor, etc. When i first noticed this I instantly thought what if I might make it sooner by not going over the network?


 When operating
When operating 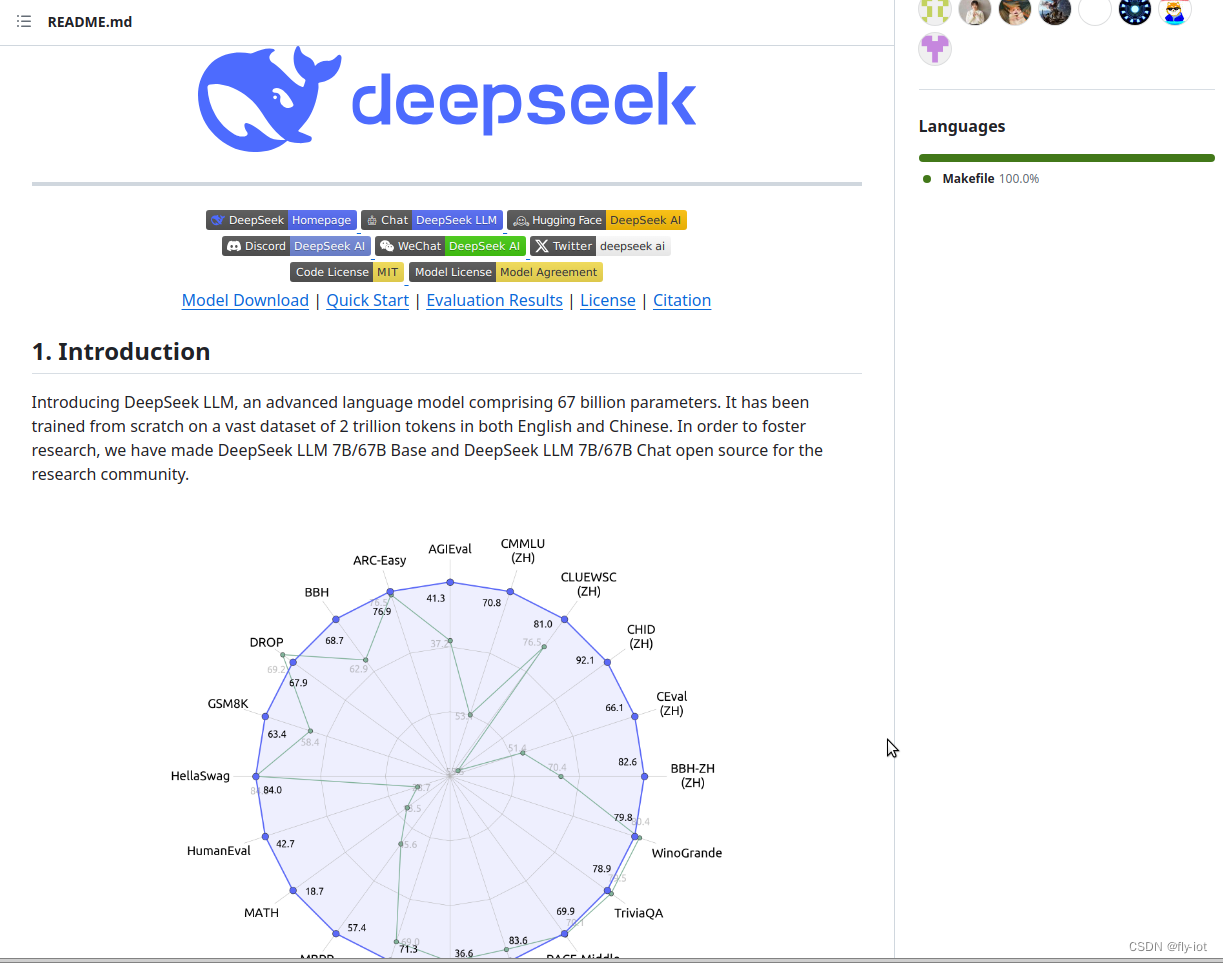 This paper examines how large language fashions (LLMs) can be used to generate and reason about code, however notes that the static nature of these models’ information doesn’t replicate the truth that code libraries and APIs are constantly evolving. These models have been pre-trained to excel in coding and mathematical reasoning tasks, achieving performance comparable to GPT-four Turbo in code-specific benchmarks. We are going to use an ollama docker picture to host AI fashions which were pre-educated for assisting with coding tasks. But like I’ve shown you, you know precisely how to use, for instance, Quen, Alarma, no matter you wanna use. Inside the browser settings as well, you can select the place you wanna document your movies. And you can truly see here like the thought course of behind it. So you possibly can see here how it is analyzing the web page with this video. We’ll hit add here and you may see the app truly works perfectly. After which from here, we can go instantly into a brand new terminal window like so and just kind that command. And from here, you can begin putting in any form of mannequin you want with AI totally free domestically. Then what you are able to do is here, go to Ollama.
This paper examines how large language fashions (LLMs) can be used to generate and reason about code, however notes that the static nature of these models’ information doesn’t replicate the truth that code libraries and APIs are constantly evolving. These models have been pre-trained to excel in coding and mathematical reasoning tasks, achieving performance comparable to GPT-four Turbo in code-specific benchmarks. We are going to use an ollama docker picture to host AI fashions which were pre-educated for assisting with coding tasks. But like I’ve shown you, you know precisely how to use, for instance, Quen, Alarma, no matter you wanna use. Inside the browser settings as well, you can select the place you wanna document your movies. And you can truly see here like the thought course of behind it. So you possibly can see here how it is analyzing the web page with this video. We’ll hit add here and you may see the app truly works perfectly. After which from here, we can go instantly into a brand new terminal window like so and just kind that command. And from here, you can begin putting in any form of mannequin you want with AI totally free domestically. Then what you are able to do is here, go to Ollama.